Introduction
Imagine an engineering team writing a relatively complex backend. Backend with multiple services, different databases, event queues, and scaling problems. They are probably writing some monolith service, splitting it into microservices, or recovering from a failed split and getting microservices back to another monolith. These services also need to interact with each other, so engineers need to maintain APIs for each of them. Or provide APIs for frontends or external customers.
Writing services is kind of repetitive, and it also involves writing a lot of boilerplate code. With this premise, last year, my friend and I started writing an open-source backend code generator called Mify.
Mify is a CLI template code generator which is mainly designed to solve two problems:
- Providing templates for batteries-included services to allow engineers to quickly start coding the actual logic.
- Maintaining APIs to enable simple service-to-service/frontend communication.
But this article is not about Mify. Here I'll only focus on the second problem.
APIs
Dealing with APIs, SDKs, and integrations is always a burden. There is a lot of boilerplate code, you have to write clients/servers, think of retries, authentication, track protocol updates, and so on.
To solve the boilerplate issue you can use code generators, and there are a lot of great tools for that, like openapi-generator. OpenAPI itself is a great way to define API without having to duplicate models in different languages, I'm biased here, I'm a fan of schema-first development, so I think this tool is quite handy.
So, in Mify we took openapi-generator to handle server/client generation for REST APIs. We're using it in a specific way:
- Continuously updating API-related codegen on schema changes. I think this is a common use case, we used it similarly before in products we've been working on.
- Overridden templates to add our custom code.
- Separated generated handlers from other generated code so that users can edit them, but not edit the internal code.
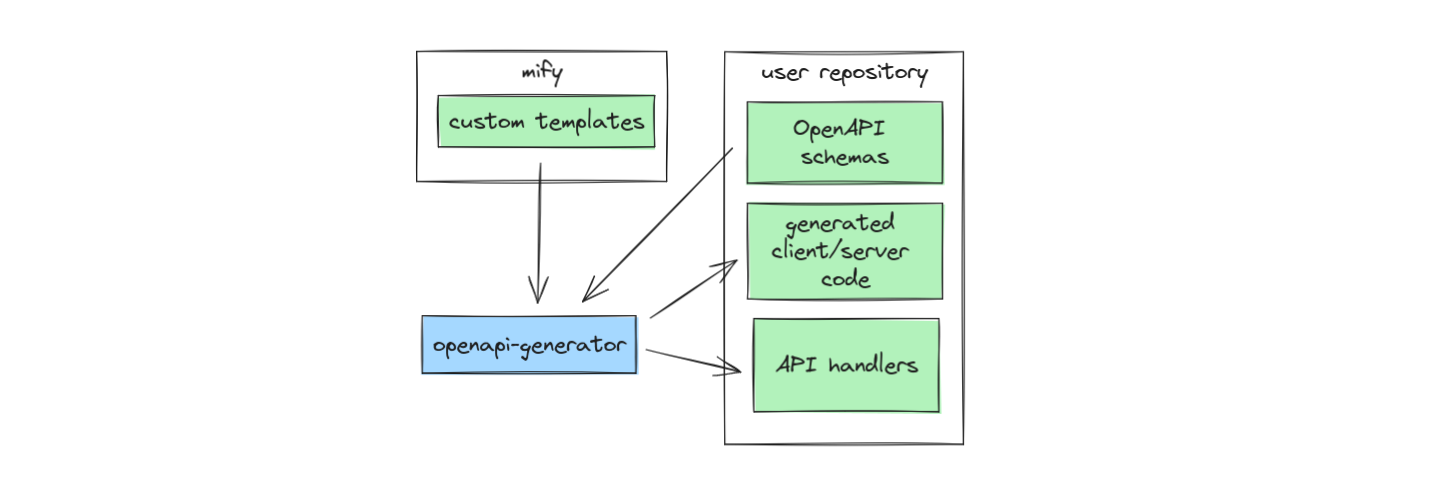
openapi-generator does its job, but for this use case, it has problems. Granted, we may have used it in the wrong way, but I've wanted to highlight some noticeable problems and propose a way to solve them to improve the generator. Here are the problems we've seen:
- The generator has an N x M problem. It needs to not only support multiple languages, but different frameworks for each language.
- It is hard to embed it in another tooling, it has a dependency on Java runtime, and it can’t be used as a library. We settled on using it as a CLI wrapped in a docker container, which adds overhead and reduces performance.
- There are too many generated files, code is mixed with implementation and different helpers, there is no distinction between editable code and non-editable code, essentially openapi-generator has a fire-and-forget model by default.
- Probably biased, but for us mustache and handlebars formats are quite complex and unreadable.
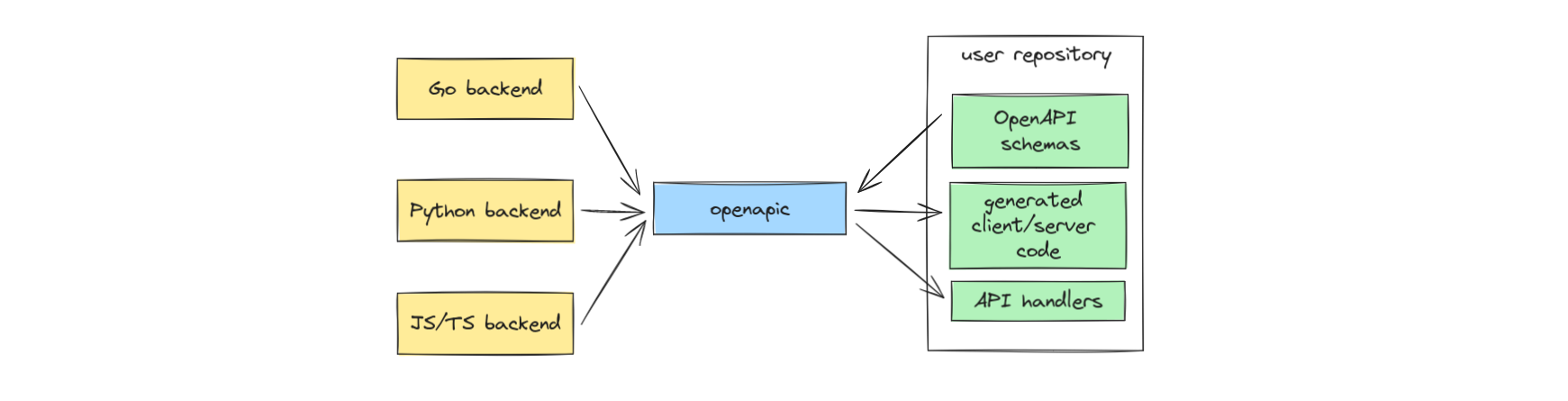
Because of these problems, we want to propose a different kind of generator, which is more akin to a compiler for openapi schemas. Essentially, this would be a protobuf-compiler for OpenAPI.
Before starting working on it, however, I want to check with the community to get feedback on this and see if we’re missing something. This post is essentially a design doc for this compiler.
Right now, we have a repository with a PoC for it, not much is there, it's just the skeleton for the most part, but you can still check it out: https://github.com/mify-io/openapic/.
Goals
Here’s the list of goals that we want to have in openapic:
- Embeddable and usable as a library: We’ll write it in Rust for that, and it will also be fast because of this (at least from the start-up time perspective).
- Minimal amount of generated code, only necessary code for types, serialization, and deserialization.
- Plugins support, which should address the N x M problem.
- Less moving parts in generated code, ideally we don’t want to allow changing templates on the fly, customization should be done with plugins.
Considered alternatives
Is it possible to use the openapi-generator in the desired way?
It has quite a lot of configuration options. For most language templates it has the option to disable parts of a template, e.g. you can generate only models, only handlers, etc, but after tinkering with that option I still noticed that it generates too much stuff, moreover, if you disable the other parts you'll need to fully implement them for each of the languages.
Another option that is supported by some languages is called interfaceOnly. It would skip generating stubs for handlers, but it will still mix framework-specific parts with the code. It is probably worth exploring adding generic language templates to openapi-generator that don't have dependencies on specific frameworks.
You can also get an existing template and modify it, but that would force to you manually add any upstream changes from the openapi-generator repository.
After trying all these options in Mify, I think the better approach would be to write (yet) another generator, which is more suitable for this use case. Next, I’ll describe implementation in detail.
High-level architecture
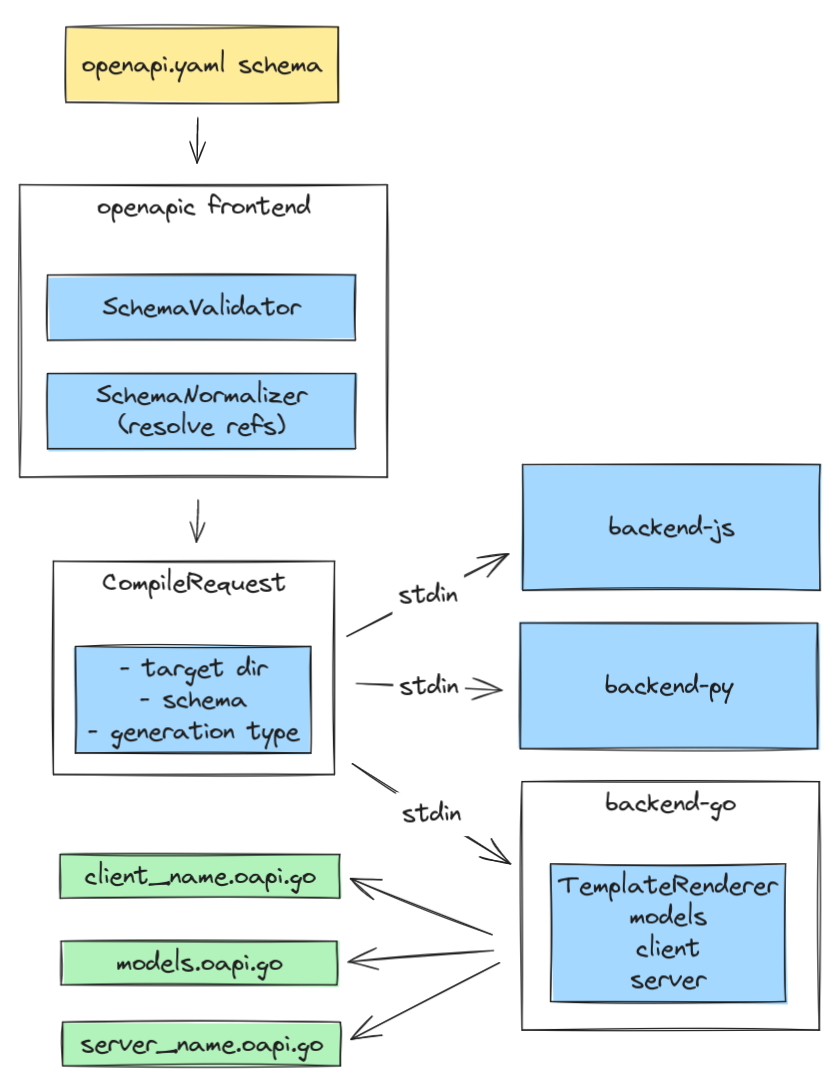
This is a high-level description of the generator. Mainly it will be split into two components:
- frontendc - this module consists of two components:
- SchemaValidator - processing the arguments and checking the schema.
- SchemaNormalizer - Resolver to read all refs in a single schema. I'll expand on this later.
- backendc - this is where all the rendering logic will be located. We would have backends roughly per each language, they will receive schema and arguments through stdin via the CompileRequest struct, which will contain already processed schema.
Generator input and output
The generator will take one OpenAPI schema yaml file at a time. By yaml schema, we understand the usual OpenAPI file like this:
# myservice_api.yaml
openapi: "3.0.0"
info:
…
paths:
/pets/:
post:
...
get:
...
components:
schemas:
Pet:
type: object
...
CreatePetRequest:
...
CreatePetResponse:
...
For this file, we’ll generate models with a client, or a server without creating a lot of files, one for models, one for client/server:
myservice_api_models.oapi.<lang>
myservice_api_client.oapi.<lang>
myservice_api_server.oapi.<lang>
CLI Usage
CLI interface should be pretty straightforward:
openapic generate models|client|server|both --output-path=dir [--package-name=package]
Open to more suggestions on this, and what else could be useful to add.
Processing the schema
Now, here’s a rough description of how we’ll process the OpenAPI schema. I’ll use pseudocode as an example of how the generated code might look like.
Schema normalization
OpenAPI allows users to split the schema definition into multiple files. Any component defined in the schema can have a reference pointing to a separate file. To simplify the schema rendering first we want to gather all components in one place, and this is what we'll mainly do in the frontendc layer. The Backendc layer will just take the processed schema and use it for rendering. Now let's go over to rendering.
Models
For each model, we’ll generate a model definition and serialization/deserialization logic with defaults and some validation:
struct CreatePetRequestBody {
pet_name string
pet_type int
}
serialize(CreatePetRequestBody r) JSON {
// In the serialize function we'll generate the setters for default values
r.pet_type = 1; // default (cat)
}
deserialize(JSON json) CreatePetRequestBody {
// same in the deserialize function
CreatePetRequestBody r;
if json["pet_type"] == nil {
r.pet_type = 1;
}
...
return r;
}
As for request/response models, I think that we need to avoid creating methods with many parameters because this will make backward compatibility harder during code regeneration. So each function will take a single struct for a request, e.g. CreatePetRequest which will contain headers, query/path params, and the request body inside. Same for the response.
struct CreatePetRequest {
Body CreatePetRequestBody
Headers CreatePetRequestHeaders
Params CreatePetRequestParams
}
Let’s move to the client and server implementation.
Client
First, for both client and server we’ll take the list of operations, and, either using the operationId or path + method, we’ll get the list of possible hander names and create interfaces:
interface PetClient {
// operationId: createPet
// or we can use path, e.g. if we have path /pets/ with post method, it'll be petsPost
CreatePetResponse createPet(CreatePetRequest req);
}
interface PetServer {
CreatePetResponse createPet(CreatePetRequest req);
}
For the client, we’ll provide the default implementation, which will essentially boil down to this:
ClientImpl {
CreatePetResponse createPet(CreatePetRequest req) {
req_json = serialize(req);
resp_json = http_client.make_request(method, req_json);
return deserialize(resp_json);
}
}
Because we’ll provide an interface for it, anyone will be able to wrap the client into something that can collect logs and metrics, or do any additional logic you want.
Server
For the server code, we don’t want to generate the full implementation for handling and parsing requests as it will force us to support multiple frameworks for each language, and it will always constrain users.
What we’re thinking of is generating framework-agnostic components to help people quickly build the server. So, as described before, we’ll generate models with serialization/deserialization, for types, requests, and responses, we’ll provide an interface for service, and we’ll have some kind of mapping of paths to operations, to help you map routes.
Pseudocode:
route_map = {
"/pets": createPet,
}
// your server code
for route, operation_func in route_map {
router.add(route, handler_wrapper(operation_func));
}
handler_wrapper(httpRequest, operation_func) {
req_json = deserialize(http_request);
resp = operation_func(req_json);
send_response(serialize(resp));
}
Plugins or backends
We want to have support for plugins as well. Plugins are essentially our backendc layer. They will be implemented as separate executables, which we’ll be calling from openapic, providing prepared schema data in request. In a plugin, you’d be able to parse additional fields defined as x-custom-field in a schema and generate code to a different language.
Embedding the generator
Rust allows for simple embedding of library API, there are a lot of bindings generators, like pyo3 for Python.
Conclusion
So that's it for the overview, I'm looking forward to more discussion about this project, feel free to leave comments and visit our Discord channel and check the current repo.